


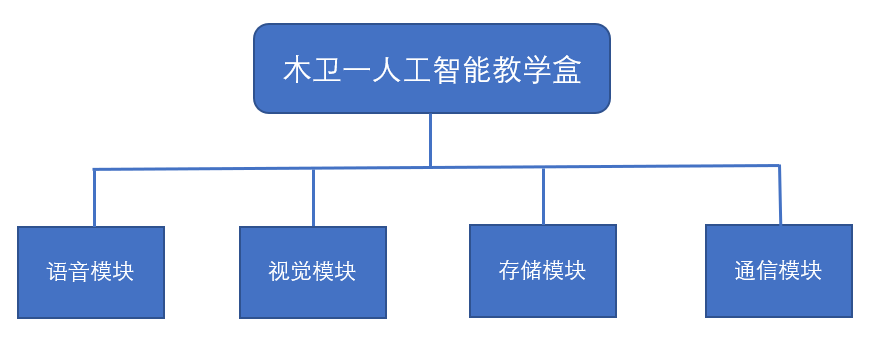
1 语音模块
语音模块由声音采集与输出两部分组成。在自然语言识别方法上,本项目使用了基于Sphinxbase库的CMU Pocketsphinx语音识别模型。本项目的语音识别系统使用最新版本“sphinxbase-5prealpha”构建应用程序。使用gstreamer自动将输入的音频分割成要识别的语音,并提供启动和停止识别的服务。语音识别系统需要特定的语言模型和字典文件,可以从自然语句的语句语料库中自动构建这些模型和文件。对于文本到语音转换(TTS),本项目机器人使用了CMU Festival系统和ROS Sound_Play软件包。
为了提高在噪声环境下的语音识别精度,在CMU Pocketsphinx语音识别模型中使用了Sphinxtrain工具来训练在噪声环境下的句子录音。Sphinxtrain工具通过使用大量上述记录作为数据库来提取嘈杂环境的声音。使用获得的参数来代替原始参数,以更好地进行语音识别检测。
2 视觉模块
视觉图像处理需要实现对目标的实时分类和识别,要求图像传感器具有较好的动态性能和较高的图像质量。另外,对于一些测距或空间立体视觉处理的功能,还要求有深度信息。综合考虑,木卫一平台配置了3D立体视觉相机。
人脸信息识别。利用OpenCV库实现人脸的检测、训练和识别。利用OpenVino模型库中的模型还能完成人脸表情、年龄、性别、朝向等的识别。
物体识别系统。该机器人使用YOLO方法来检测物体。在模拟仓储物品识别的任务中,机器人使用3D立体视觉摄像机进行货架检测、桌子检测和目标检测。在实际识别之前,机器人对预先定义的对象进行拍照,然后通过为每个图像添加注释标签和边界框来进行标记。机器人需要捕捉不同角度、不同光照条件以及不同背景下的图像,以确保实际使用的模型符合复杂的真实工作环境。
人体姿态检测。在人体姿态检测系统中,本项目使用卡耐基梅隆大学的OpenPose作为骨架检测方式。它是一个用于身体、面部、手和脚估计的实时多人关键点检测库。OpenPose需要一幅RGB图像,然后返回人员数量及其骨架位置。为了得到人体的指向,需要知道手腕关节和肘关节的三维坐标。将OpenPose结果与点云库(PCL)相结合,得到机器人顶端3D立体视觉摄像机坐标系中所描述的位置,然后利用TF矩阵将其转换为地图坐标系。此外,空间矢量法被用来计算人指向地面上的哪个点。
3 存储模块
存储模块采用可高速读写的固态存储介质,读写速度可达400MB/s,保证木卫一即插即用的同时,系统能流畅运行,提高开发效率。存储模块中装有Ubuntu系统、ROS及相关使用软件,配置好了完整的驱动和功能包,包括图像处理、语音识别、机械臂运动仿真、室内建图与导航仿真的所有功能。支持UEFI和Legacy双启动模式,USB3.0连接即可快速启动系统,支持系统一键还原。
系统仿真平台配置有一套7自由度机械臂运动规划案例,可完成MoveIt!运动规划解算。另外配置有两套虚拟家居环境,可以完整实现机器人SLAM建图和自主导航。支持gmapping、karto二维SLAM和rtabmap三维地图构建;支持各类路径规划算法,导航参数可自主调节。
4 通信模块
使用USB3.0及以上端口直接供电和进行数据通信;平台自带150M wifi模块,支持远程控制。
我司产品均提供一年上门保修服务,保修范围包括非人为原因造成的硬件损坏和数据缺失。
每年提供1次免费的原厂数据拯救服务。